
World Models 101: The Environment Layer Your AI Agent Has Been Missing
What world models are, how they work, and what changes for AI PMs when simulation enters the stack

The first time I heard “world models,” I was listening to my own AI-generated podcast. The one my n8n workflow produces automatically: scrape AI news, have Claude write the script, send it to ElevenLabs for audio.
I paused. Wait, what? Did I hear that correctly?
My genuine first reaction was that Claude’s API had hallucinated again. Made up a term that sounded impressive but didn’t exist. I’ve caught it doing that before.
But I searched it. And it was real. And the more I read, the more I realized this was a concept I needed to understand properly, not just nod along to.
So I did my research. This post is what I found.
What you’ll learn (9-minute read):
Why “world model” means three different things right now (and which one you’ll actually encounter)
The core building blocks: perception, dynamics, and planning
How world models differ from LLMs and agents, and how they fit together
Where world models are showing up in real products today
What changes for AI PMs when world models enter the stack
A practical Phase 1/2/3 roadmap for thinking about this in your product

The Terminology Problem
“World model” is one of those terms where you can spend 30 minutes searching and come out more confused than when you started. I’ll save you that experience.
The term means three different things depending on who’s using it.
Yann LeCun’s framing: A learned internal representation of how the world works. Physics, causality, 3D space, object permanence. The things humans internalize from infancy. LeCun (Meta’s Chief AI Scientist) has spent years arguing that this is the missing ingredient for human-level AI.
Video generation framing: Models like Sora (no longer an OpenAI offering) are called “world models” because they’ve apparently learned enough about physical dynamics to generate realistic video sequences. This is contested. Some researchers argue that predicting pixels isn’t the same as understanding physics.
Robotics and simulation framing: A differentiable simulator that an agent can use to run rollouts before taking real actions. This is the most concrete version and the one with the most immediate product relevance.
These are related but not identical. For this post, I’m focused on the third framing. World models as a simulation and planning infrastructure. The others are worth knowing about (I covered the LeCun framing in my Q1 2026 AI Vocabulary List), but if you’re building products, the simulation framing is where this gets real.
What a World Model Actually Does
Plain language: a world model is an internal simulator that lets an AI predict how the world will change before it acts.
Here’s where the concept clicked for me.
A warehouse robot needs to navigate around an obstacle to reach a package. Without a world model, the robot tries a path. Bumps into something. Backs up. Tries again. Learning from interaction. That works, but it’s slow, it causes wear, and in a hospital corridor or factory floor, it can be unsafe.
With a world model, the robot simulates 10 possible paths before it moves a single motor. It predicts which paths hit obstacles, which ones are fastest, which ones minimize risk. Then it picks the best one and moves.
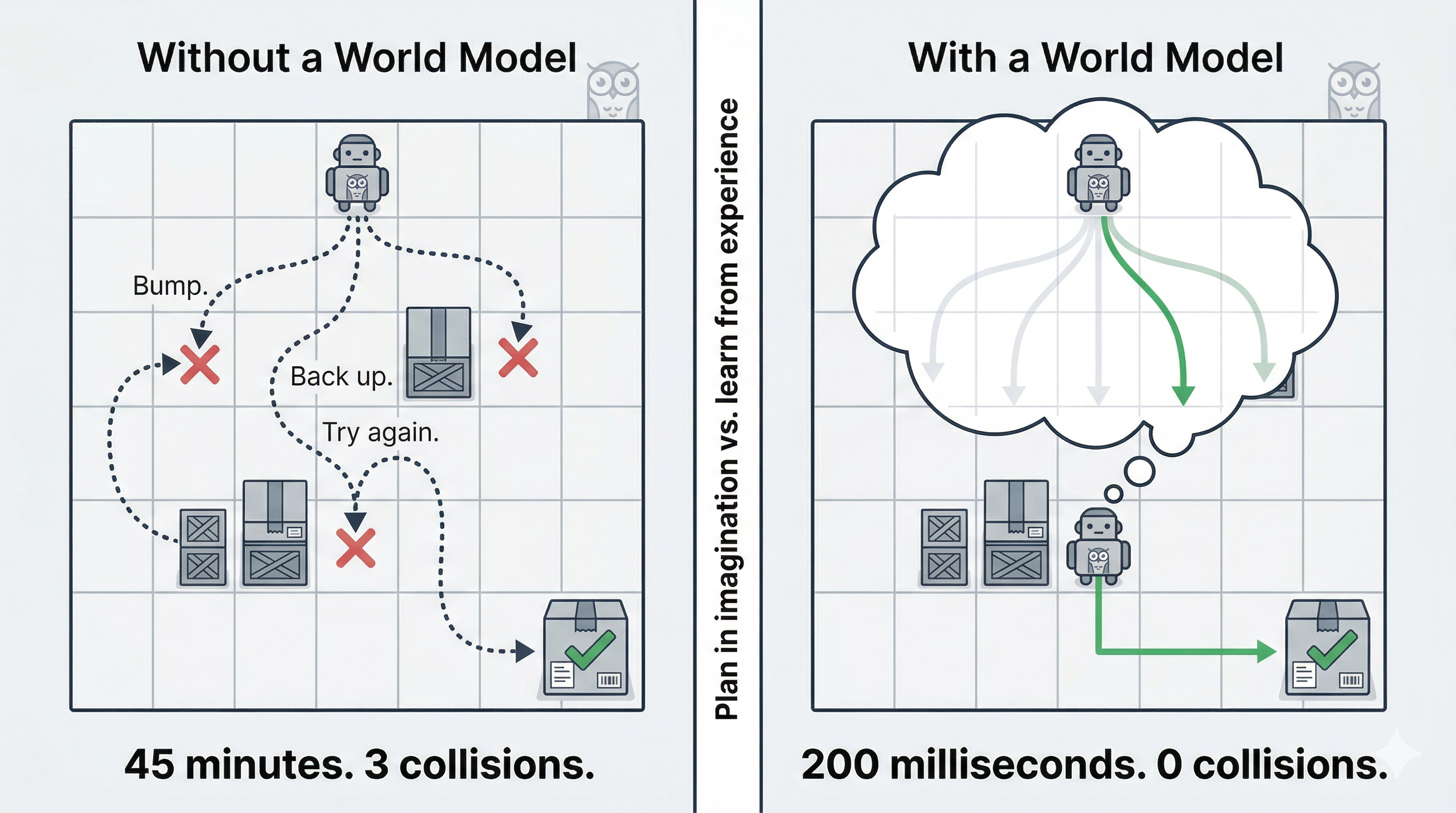
That’s the core capability. Planning in imagination instead of only learning from experience.
A bit more technical: a world model takes a current state and an action as inputs, and predicts the next state. Sometimes it also predicts a reward signal. This lets an agent plan across sequences of actions, not just react to what’s in front of it.
How World Models Work: Three Building Blocks
Most world model architectures have three components. I’ll walk through each one using the warehouse robot, because the abstraction makes a lot more sense with a concrete example running through it.
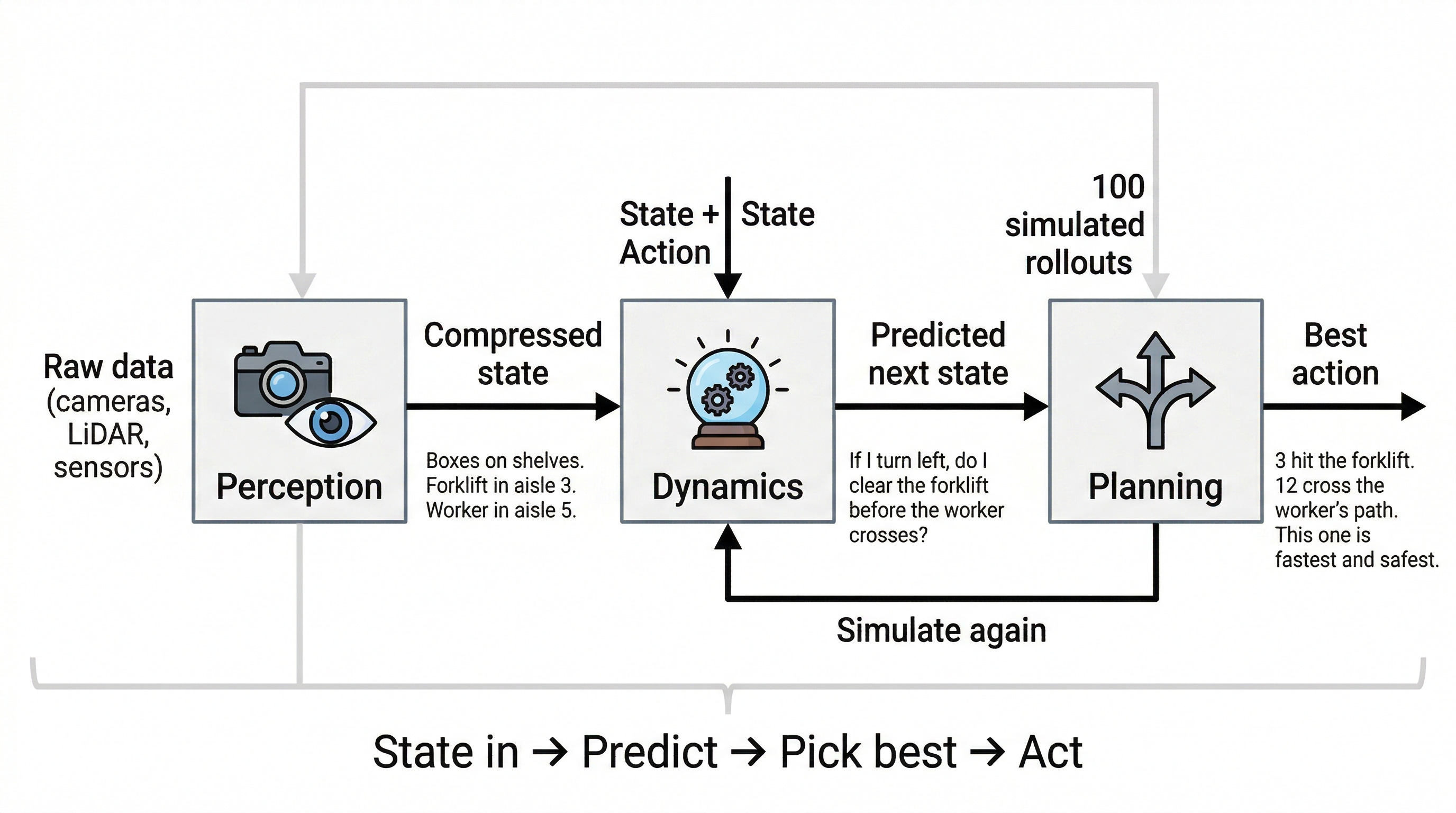
Perception: What’s Happening Right Now?
The robot is getting camera feeds, LiDAR scans, and sensor readings simultaneously. That’s a massive amount of raw data. Perception converts all of it into a compact representation of “what’s going on right now.”
For the warehouse robot, that means taking the camera feed showing boxes on shelves, a forklift blocking aisle 3, and a worker walking through aisle 5, and compressing it into a state representation that the rest of the system can work with. In ML terms, it encodes the environment into a latent state. The goal: capture what matters without carrying every raw pixel.
A quick note on computer vision vs. world models:
Computer vision answers: What am I looking at? A world model answers: what happens next if I do X, and which X is best?
In our warehouse robot, computer vision is the part that says “forklift in aisle 3, worker in aisle 5.” That’s perception. The world model runs 100 simulated futures for each of the following: if I turn left, if I go straight, and if I wait 3 seconds. Computer vision is the eyes. A world model is the eyes, plus imagination, plus judgment.
Dynamics: What Happens Next?
This is the world model proper. It takes the compressed state from perception and predicts what happens next, given an action. If the robot turns left, what does the world look like in 500 milliseconds? If it speeds up, does it clear the forklift before the worker crosses?
This is where the physics, object permanence, and environmental behavior get encoded. A good dynamics model generalizes: it can predict states it never saw in training, not just memorize transitions. That generalization is what makes simulation useful. Without it, you’re just replaying recorded scenarios.
Planning: Which Path Is Best?
The planner uses the dynamics model to look ahead. Run 100 simulated rollouts. Score each one. Pick the action sequence that leads to the best outcome.
For the warehouse robot: simulate 100 possible routes in 200ms of compute time. Three routes hit the forklift. Twelve routes cross the worker’s predicted path. The planner picks the route that reaches the package fastest while minimizing collision risk. All of that happens before the robot moves an inch.
Compare that to 45 minutes of physical trial and error. That’s the business case for world models in a single number.
If you’ve read my AI Architecture Patterns 101 post, you’ll recognize the Think → Plan → Act → Observe loop for agents. World models make the “Plan” step dramatically more capable. Right now, most agents plan by reasoning over text and tool descriptions. With a world model, they plan by simulating what will actually happen.
Different categories of capability.
