
What I Learned Preparing to Explain RAG vs. Fine-Tuning in an AI PM Interview

“What’s the difference between RAG and fine-tuning? When would you use each?”
This came up in my third mock interview and I fumbled it. I knew both concepts individually. I could explain what RAG does. I could explain what fine-tuning does. But when asked to compare them and offer a decision framework for choosing between them? I rambled for about two minutes without landing anywhere useful.
So I spent the next week getting clear on this. Here’s what I wish I’d known before that interview.
What You’ll Learn (7-minute read)
The core difference between RAG and fine-tuning (it’s simpler than most explanations make it)
A decision framework for choosing between them
What interviewers are actually testing with this question
Follow-up questions to prepare for
Common mistakes that signal shallow understanding
Why This Question Matters
RAG and fine-tuning are the two main ways to customize LLM behavior for a specific use case. Every AI product team faces this architectural decision at some point. And getting it wrong is expensive in different ways depending on which direction you go.
Choose RAG when you should have fine-tuned? Your product might feel generic or miss domain-specific nuances in its communication. Choose fine-tuning when RAG would have worked? You’ve spent months and significant compute on something you could have shipped in weeks.
Interviewers ask this because they want to know if you can make architectural decisions and understand the trade-offs involved. It’s a judgment question dressed up as a technical one.
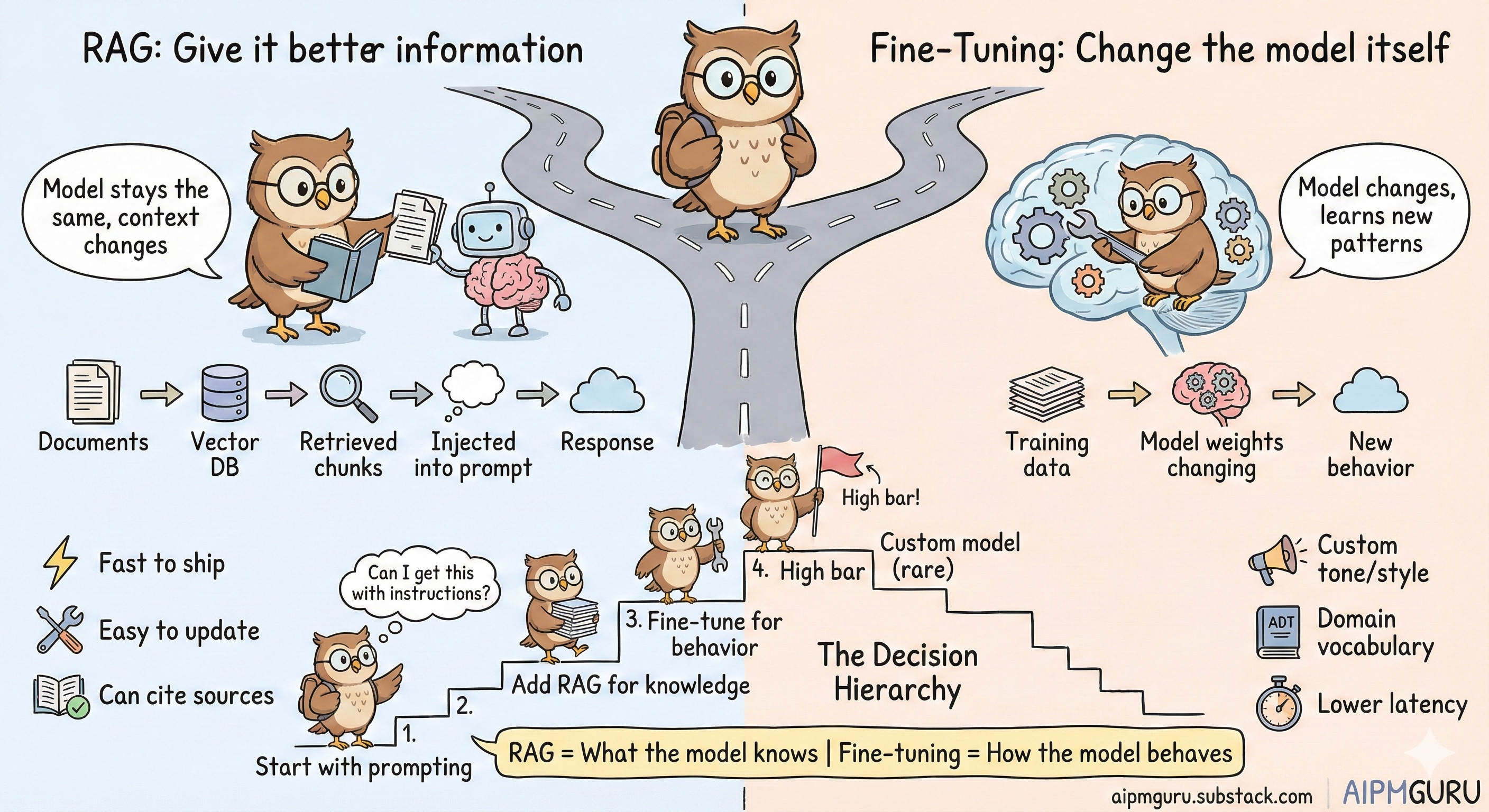
The Core Difference
Here’s the mental model that finally made this click for me.
RAG keeps the model the same but gives it better information. You retrieve relevant documents based on the user’s query and inject that context into the prompt. The model’s weights don’t change. It just gets more relevant input to work with.
Fine-tuning changes the model itself. You train it further on your specific data, which modifies the model’s weights. This changes how the model behaves, its patterns, its style, its domain vocabulary.
Think of it this way: RAG is giving someone a reference book before they answer your question. Fine-tuning is sending them to specialized training so they think differently about the domain.
Both improve outputs. But they’re solving different problems, and that distinction is what interviewers want to hear you articulate.
When RAG Is the Right Choice
RAG shines when the issue is knowledge, not behavior.
Your model needs access to specific, updatable information. Company documentation, product catalogs, support articles, policy documents. Anything that changes over time or is specific to your domain. RAG handles this well because you’re not baking information into the model. You’re feeding it relevant context at query time.
You need to cite sources. RAG naturally supports this because you know exactly which documents informed the response. A fine-tuned model can’t tell you where its knowledge came from. For regulated industries or products where trust matters, this is a big deal.
You want to ship fast. RAG can be implemented in days or weeks. Embed your documents, set up a vector database, build a retrieval pipeline, and you’re generating grounded responses. I covered RAG architecture in more detail in my post on unlocking the power of AI with Retrieval-Augmented Generation, and the vector database side of things in Vector Database 101.
Your knowledge base will change. Update the documents, re-embed them, and the model immediately has access to new information. No retraining. No versioning headaches. For most product teams, this alone makes RAG the default starting point.
When Fine-Tuning Makes Sense
Fine-tuning is the right call when the issue is behavior, not knowledge.
You need a specific tone or style that prompting can’t achieve. Maybe your brand voice is distinctive, or you need the model to consistently produce outputs in a particular format. If you’ve tried extensive prompt engineering and still can’t get the behavior right, fine-tuning might be the answer. I wrote about this in more detail in my fine-tuning piece.
You have domain-specific vocabulary or reasoning patterns. Legal, medical, or highly technical domains sometimes have terminology and conventions that base models handle awkwardly. Fine-tuning on domain examples can help the model internalize these patterns rather than needing them spelled out every time.
Latency matters and you can’t afford long prompts. RAG adds to prompt length because you’re injecting retrieved context. A fine-tuned model that has “learned” the domain might generate faster because it skips the retrieval step entirely. For real-time applications, this matters.
You’re operating at scale where prompt tokens get expensive. If every query requires injecting 2,000 tokens of context, and you’re handling millions of queries, the cost adds up. A fine-tuned model might be more economical at that volume. Though honestly, do the math before assuming this. The fine-tuning costs (data prep, training compute, evaluation, ongoing maintenance) aren’t trivial either.
The Decision Framework
Here’s my default approach, which is what I now articulate in interviews:
Start with prompting. Can you get acceptable results with a well-crafted prompt? System instructions, few-shot examples, output format specifications? Try this first. It’s fast, cheap, and reversible.
Add RAG when you need domain knowledge. If the model lacks specific information, it needs to answer well; RAG is usually the answer. This is the most common pattern in production AI products from what I’ve seen.
Consider fine-tuning when you’ve hit the limits of RAG and prompting. If you’ve optimized your prompts, built a solid RAG pipeline, and still can’t get the behavior you need, then fine-tuning might be justified.
Build custom models only with clear evidence. Training from scratch or heavy fine-tuning requires substantial data, compute, and ongoing maintenance. The bar should be high.
This hierarchy isn’t arbitrary. Each step up increases cost, complexity, and time to iterate. Start simple. Add complexity only when you have evidence that it’s needed. That’s the kind of thinking I believe interviewers want to see from a PM.
What Interviewers Are Listening For
Beyond the technical content, I think this question is really testing a few things.
You understand the mechanisms, not just the buzzwords. Explaining that RAG provides context while fine-tuning changes weights shows you grasp what’s actually happening. A lot of candidates can name both approaches but can’t explain the difference at a mechanical level.
You have a decision framework. Interviewers want structured thinking, not “it depends.” Having a clear hierarchy (prompting → RAG → fine-tuning) shows you can make pragmatic architectural decisions and defend them. This also allows you to ask the right questions in those architectural meetings with your team.
You think about trade-offs. Cost, iteration speed, updateability, maintenance burden. Mentioning these signals you understand the full picture, not just capability.
You default to simplicity. If your first instinct is “let’s fine-tune,” that’s a red flag. If your first instinct is “let’s see if we can get there with prompting and RAG first,” that signals practical judgment.
Common Mistakes to Avoid
A few things I’ve noticed (in my own prep and in feedback from mock interviews) that weaken this answer.
Confusing what each approach does. I’ve heard candidates describe fine-tuning as how you “add knowledge” to a model. That’s not quite right. Fine-tuning changes behavior patterns. If you need the model to know specific facts, RAG is usually better because the knowledge is explicit, updateable, and citable.
Not having a framework. Just explaining what RAG and fine-tuning are, without guidance on when to use each, misses the point. Interviewers are testing judgment, not definitions. I learned this the hard way in that third mock interview.
Ignoring the hidden costs. Fine-tuning sounds appealing until you account for data preparation, training compute, evaluation, ongoing monitoring, model versioning, and the difficulty of updating when information changes. These costs are real and they compound.
Treating them as mutually exclusive. You can fine-tune a model AND use RAG with it. A fine-tuned model for style plus RAG for domain knowledge is a valid production architecture. Mentioning this shows sophistication.
Follow-Up Questions to Expect
“Walk me through how you’d architect a RAG solution for our documentation.” They want to see if you understand the components: document chunking strategy, embedding model selection, vector database choice, retrieval tuning, prompt construction with retrieved context. You don’t need to know every implementation detail, but you should understand the pipeline and the decisions at each step.
“How would you evaluate whether fine-tuning is working?” This tests whether you understand evaluation. Key points: hold out a test set, define metrics that matter for your use case (not just training loss), compare against the base model and prompting-only baselines, and watch for overfitting or catastrophic forgetting (where the model gets better at your task but worse at everything else).
“We have 10 years of customer support tickets. How would you use this data?” This is a trap question. Having lots of data doesn’t automatically mean fine-tuning. I’d answer: first, use this data to build a RAG system so the model can reference past resolutions. Then analyze whether there are consistent tone or format patterns we can’t achieve through prompting. Only then would I consider fine-tuning, and probably on a small subset focused on style rather than trying to encode all that knowledge in weights.
The Nuance Worth Adding
If you want to show deeper understanding and the conversation allows it, mention that “fine-tuning” exists on a spectrum.
Full fine-tuning updates all model weights. Expensive, powerful, and comes with real risk of breaking things the model already does well. LoRA and other parameter-efficient methods update only a small subset of weights. Cheaper, faster, lower risk. Most production fine-tuning I’ve read about uses these approaches rather than full fine-tuning.
There’s also prompt tuning, which learns optimal prompt embeddings while keeping the model frozen entirely. And distillation, where you train a smaller model to mimic a larger one for deployment efficiency.
Knowing this spectrum exists shows you understand the options aren’t binary. You don’t have to go deep on the mechanics, but being aware that there’s a range between “do nothing to the model” and “retrain everything” demonstrates real understanding.
What’s Next
This question is really about architectural judgment. Can you evaluate trade-offs? Can you recommend an approach and defend it? Can you resist the temptation to reach for the most complex solution first?
Practice articulating the prompting → RAG → fine-tuning hierarchy. Know why each step exists and what evidence would push you to the next one. Be ready to walk through a specific scenario.
And remember what I had to learn the hard way: the best answer isn’t the most technically impressive one. It’s the one that shows you’d make good decisions for the product and the team.
What architectural decisions are you wrestling with in your AI PM interview prep? I’d love to hear what trade-offs you’re navigating.
"Start with prompting, advance to RAG, then consider fine-tuning only when earlier approaches prove insufficient" - this ladder is the answer to 90% of "should I fine-tune" questions I hear.
The mistake I keep seeing: teams jump to fine-tuning because it feels more technical and impressive, not because prompting or RAG actually failed them. Fine-tuning a model that was never given proper context is optimizing the wrong layer entirely.
One thing worth adding to the framework: the hybrid approach works but evaluation complexity compounds fast. You need separate metrics for whether RAG retrieves the right context AND whether the fine-tuned model handles it correctly. Debug surface area doubles overnight.