
Understanding the Differences: Large Language Models vs. Traditional Machine Learning

As the field of artificial intelligence (AI) continues to evolve, it becomes increasingly important to distinguish between the various types of models that drive innovation. Two key players in this domain are Large Language Models (LLMs) like OpenAI's GPT series, and traditional Machine Learning (ML) models, encompassing a broad range of algorithms from linear regression to deep neural networks. While both are instrumental in pushing the boundaries of what machines can achieve, they serve different purposes and operate under distinct paradigms.
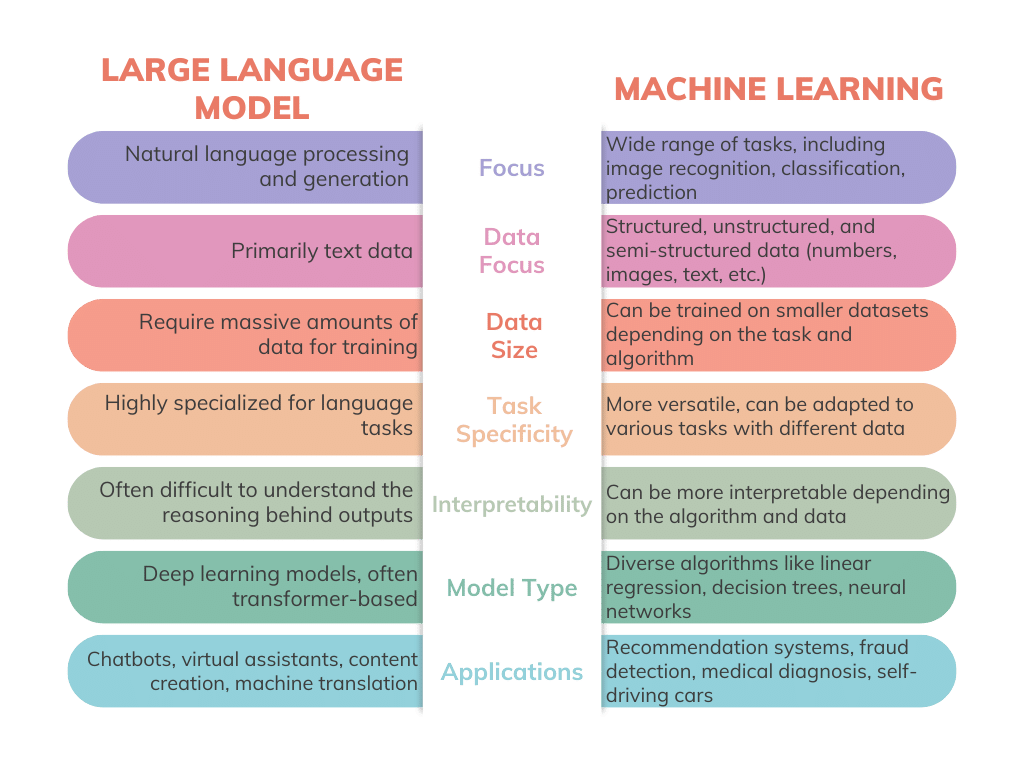
LLMs have taken the world by storm, demonstrating an uncanny ability to generate human-like text, translate languages, answer questions, and even write code. Models such as GPT-3 are based on the Transformer architecture, which allows them to process and generate sequences of data, particularly text, with remarkable proficiency. These models are trained on vast datasets comprising a wide swath of human knowledge, enabling them to mimic human writing styles, understand context, and generate coherent and contextually relevant text.
On the other hand, traditional ML models have been the backbone of AI applications for decades. These models are incredibly versatile, used in tasks ranging from predicting stock market trends to diagnosing diseases from medical images. Unlike LLMs, traditional ML models are usually trained on structured datasets specific to the problem. They can include a variety of algorithms tailored to the nature of the task, whether it be classification, regression, or clustering.
One of the main differences between LLMs and traditional ML models is their approach to training and application. LLMs undergo a two-step process: first, they are pre-trained on general tasks and then fine-tuned for specific applications. This makes them highly adaptable to various language tasks with minimal adjustment. Traditional ML models, however, are often designed and trained from scratch for each specific application, requiring significant domain knowledge and data preprocessing.
Moreover, LLMs are known for their "black box" nature due to their complexity and scale, making it challenging to decipher how they arrive at particular outputs. In contrast, some traditional ML models, such as decision trees, offer high interpretability, allowing users to understand the decision-making process clearly.
Another critical aspect to consider is the resource intensity associated with training these models. LLMs, particularly the most advanced versions, require enormous computational power and energy, raising concerns about their environmental impact. Traditional ML models can vary widely in resource needs, with some being lightweight and efficient, while others, especially deep learning models, can also be resource-intensive.
As we continue to explore the capabilities and potential of LLMs and traditional ML models, it's clear that the future of AI will likely involve a hybrid approach, leveraging the strengths of each to address complex challenges. LLMs' adaptability to language tasks and traditional ML models' specificity and efficiency in structured tasks complement each other, offering a broad toolkit for AI practitioners.