
The Invisible Upgrade: How Tokenization Quietly Got Better (And Why Your AI Costs Dropped)

I was reading Lenny Rachitsky’s latest blog post, “How to build AI product sense” by Tal Raviv and Aman Khan, when I came across this diagram of how context windows actually work across conversation turns. It’s from OpenAI’s documentation on conversation state, and it shows how each turn of a conversation adds more tokens to the context window until it is eventually truncated.
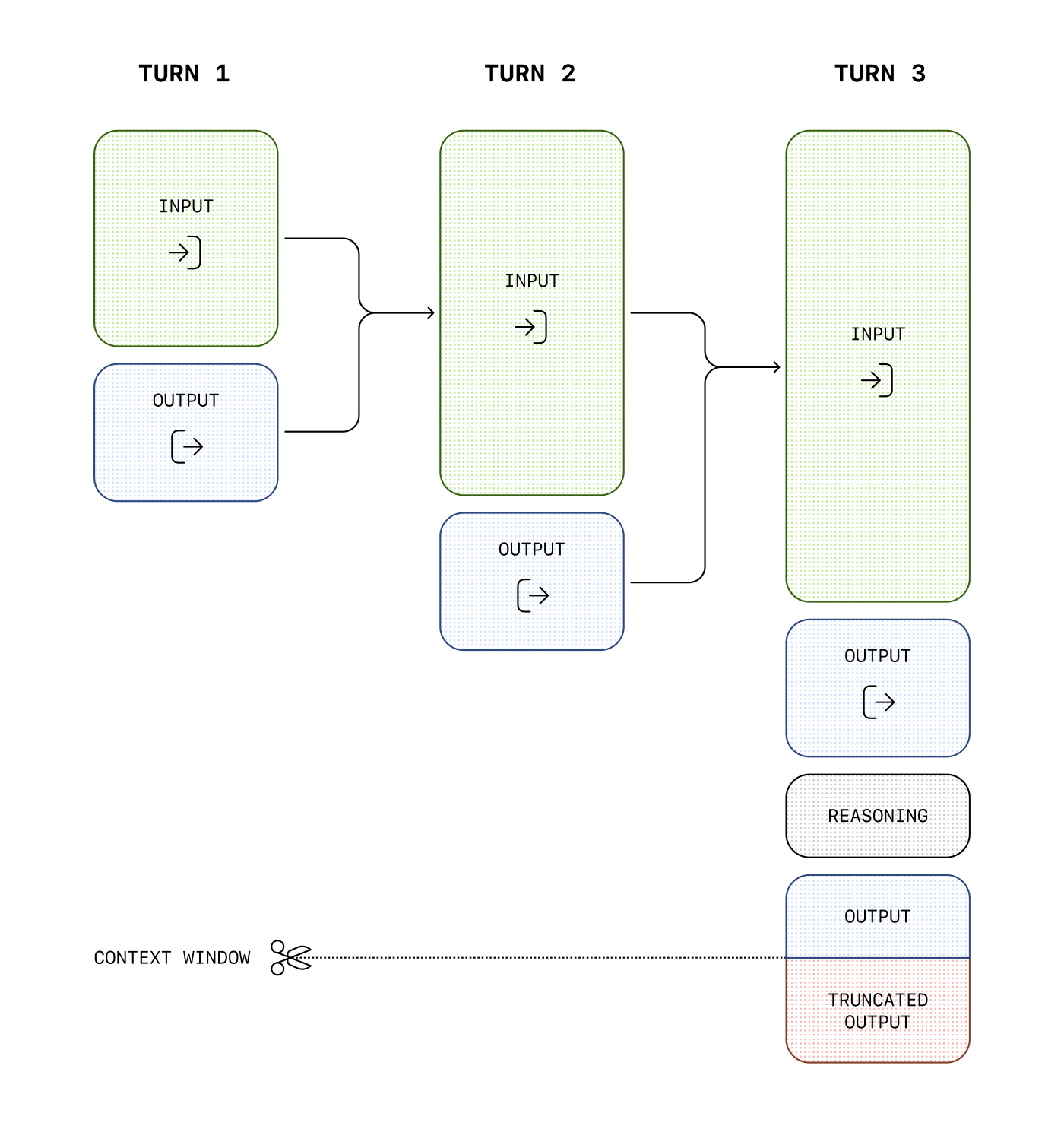
The diagram got me thinking about tokens (the units that fill up that context window), which led me to poking around OpenAI’s documentation, which led me to their Tokenizer tool.
And that’s when I fell down a rabbit hole I wasn’t expecting.
I pasted in the tool’s default example text and toggled between model generations. Same text. Same 252 characters. But the token counts kept changing:
GPT-3 (legacy): 64 tokens
GPT-4 & GPT-3.5: 57 tokens
GPT-5.x & O1/3: 53 tokens
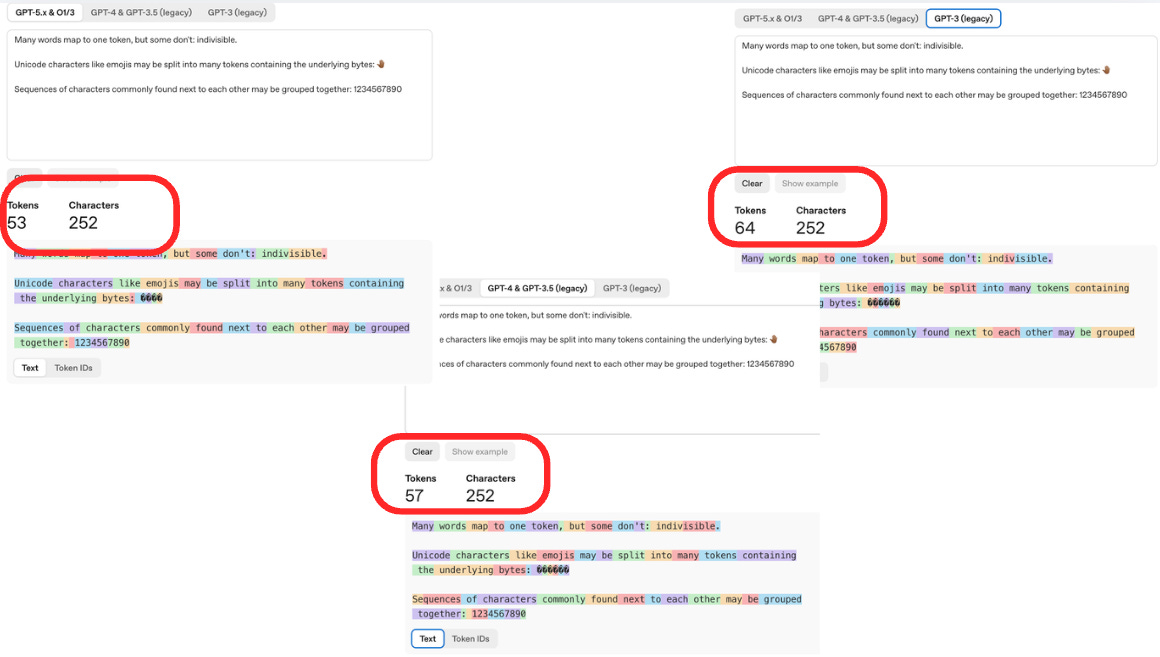
That’s a 17% reduction from GPT-3 to the latest models. For the exact same input. And I thought: wait, how? And more importantly, why does nobody talk about this?
Turns out, tokenization (how models chop up your text before processing it) has been quietly evolving across model generations. And it has real implications for cost, performance, and which languages your AI product actually works well for.
What You’ll Learn (8-minute read):
What tokenization actually is (the 30-second version)
How tokenizers evolved from GPT-2 to GPT-5.x
Why better tokenization means lower costs and better multilingual support
The tradeoffs nobody warns you about
What this means for your product decisions
TL;DR: The 30-Second Version
LLMs don’t read words. They read “tokens,” which are chunks of text. You pay per token. Your context window is measured in tokens. So how text gets split into tokens matters a lot.
OpenAI has quietly upgraded its tokenizer three times. The latest version is 86% more efficient for languages like Gujarati and 17% more efficient even for English. Same text, dramatically fewer tokens.
What this means for you as a PM: multilingual products are suddenly much cheaper to run, your context window effectively got bigger for free, and you should retest any cost or chunking assumptions based on older models.
That’s the short version. Keep reading for the how and why.
Tokens: A Quick Refresher

I covered tokens in my earlier post on Understanding AI Prompting, but here’s the short version. LLMs don’t read words. They read tokens, which are chunks of text the model has learned to recognize as units. Sometimes a token is a whole word. Sometimes it’s a piece of a word. Sometimes it’s a single character.
The sentence “I love product management” might become four tokens: [“I”, “love”, “product”, “management”]. But a word like “tokenization” gets split into [“token”, “ization”]. An emoji like 👋 might cost you 2-3 tokens.
This matters because you pay per token (both input and output), your context window is measured in tokens, and the model literally cannot “see” anything smaller than a token. As Andrej Karpathy put it in his famous tokenizer lecture: “Why can’t LLMs spell words? Tokenization. Why are LLMs bad at arithmetic? Tokenization. What is the root of suffering? Tokenization.”
He’s only half joking.
Three Generations of Getting Better at Chopping Text
Here’s what surprised me. OpenAI hasn’t just been improving the neural networks. They’ve been improving how text gets fed into the models. And the changes are significant.
Before I walk through the three generations, a quick note on what “vocabulary size” actually means, because I initially found this confusing.
Think of it like your phone’s autocomplete dictionary. When you first get a new phone, it only knows individual letters. You have to type H-e-l-l-o every time. But over time it learns that “Hello” is something you type a lot, so it stores the whole word as one suggestion. One tap instead of five keystrokes. It might even learn “Hello, how are you?” as a single prediction if you type it enough.
Vocabulary size is just how many of those shortcuts the tokenizer has learned. A 50K vocabulary has 50,000 shortcuts. A 200K vocabulary has 200,000. More shortcuts means less spelling things out, which means fewer tokens, which means lower costs and more room in your context window.
Now, you might hear “vocabulary” and “parameters” used in the same conversation and wonder how they relate. They’re connected but different. The vocabulary is like having 200,000 contacts in your phone (just names and numbers). A simple lookup table. The parameters are like actually knowing all those people: their personalities, how they relate to each other, what they’d say in different situations. The contact list is small. The knowledge about each person is where the real complexity lives.
Every token in the vocabulary gets a row of numerical weights (parameters) that represents what that token “means” mathematically. So a bigger vocabulary does mean more parameters in that one layer. But GPT-4’s total parameter count is in the hundreds of billions. The embedding table from a 200K vocabulary is a tiny fraction of that. Still, it’s a real cost, which is partly why earlier, smaller models stuck with smaller vocabularies.
OK, with that context, here’s how the three generations played out.
Generation 1: GPT-2 and GPT-3 used a tokenizer called r50k_base with roughly 50,000 tokens in its vocabulary. This was the first implementation of Byte Pair Encoding (BPE) at the byte level, which was a big deal at the time. GPT-2’s team introduced a regex pattern that prevented merges across character categories, so letters and punctuation wouldn’t get fused into weird hybrid tokens (no more “dog.” becoming a single token).
Generation 2: GPT-3.5 and GPT-4 jumped to cl100k_base, doubling the vocabulary to about 100,000 tokens. More shortcuts in the dictionary. More common sequences get their own token instead of being spelled out piece by piece.
Generation 3: GPT-4o, GPT-5.x, and all current OpenAI models use o200k_base, doubling the vocabulary again to roughly 200,000 tokens. But the vocabulary size isn’t even the most interesting part.
One important note: models and tokenizers are loosely coupled. Newer models generally use newer tokenizers, but you should always confirm which tokenizer your stack is actually using. Don’t assume.
The real upgrade was in how o200k_base handles word boundaries across different writing systems. The regex patterns were completely rewritten to include Unicode character categories like \p{Lo} (other letters), \p{Lm} (modifier letters), and \p{M} (marks and diacritics). In plain English: the tokenizer got much better at understanding where words start and end in non-Latin scripts.
You can see this playing out in the screenshots I took. Look at how the word “indivisible” gets tokenized differently across generations: GPT-3 splits it into more pieces, while the latest tokenizer keeps larger chunks together. The number sequence “1234567890” and the emoji also show visible differences in how they’re broken apart.
The Multilingual Payoff (This Is Where It Gets Wild)
The impact on non-English languages is staggering. According to an analysis published on Microsoft’s Tech Community blog, the o200k_base tokenizer showed massive efficiency gains for Indian languages:

Why? With the older tokenizer, a simple Tamil character with its diacritic mark (like நீ, meaning “you”) got split into four separate tokens. Four tokens for two characters. The new tokenizer groups the entire word together, including diacritics.
Here’s a concrete example of how dramatic this gets. I pasted a paragraph about Mahatma Gandhi in Gujarati (my first language, the one I grew up speaking before moving to the States at 14 and landing in ESL classes) into the tokenizer tool. Same text, same 691 characters, three different model generations:
GPT-3 (legacy): 1,819 tokens
GPT-4 & GPT-3.5: 1,153 tokens
GPT-5.x & O1/3: 260 tokens…say what? and it recognizes the wording! Absolutely amazing!
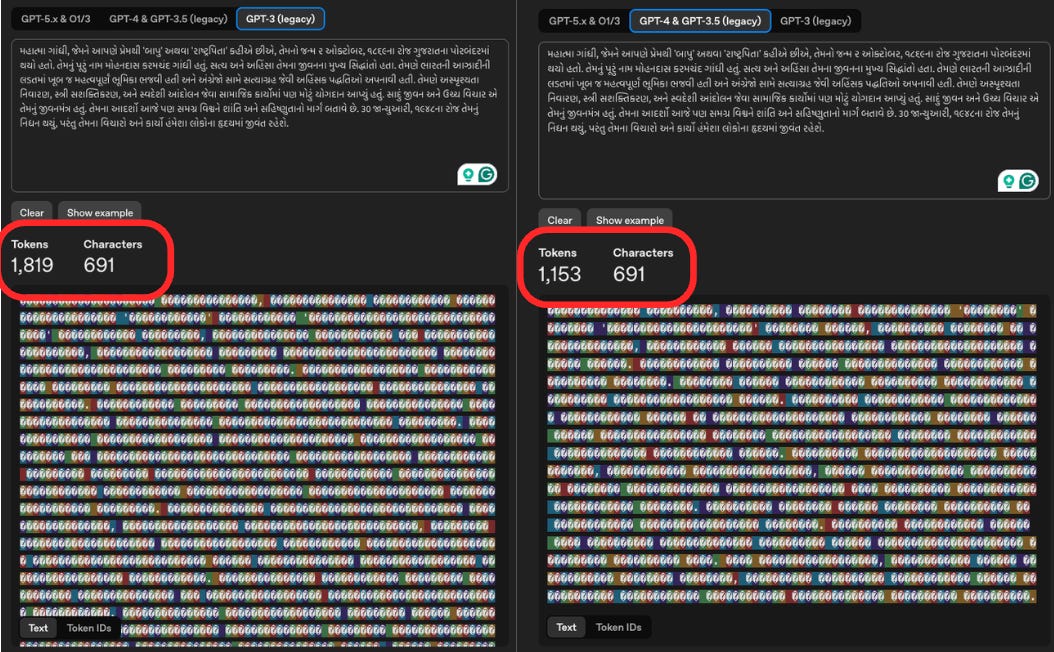
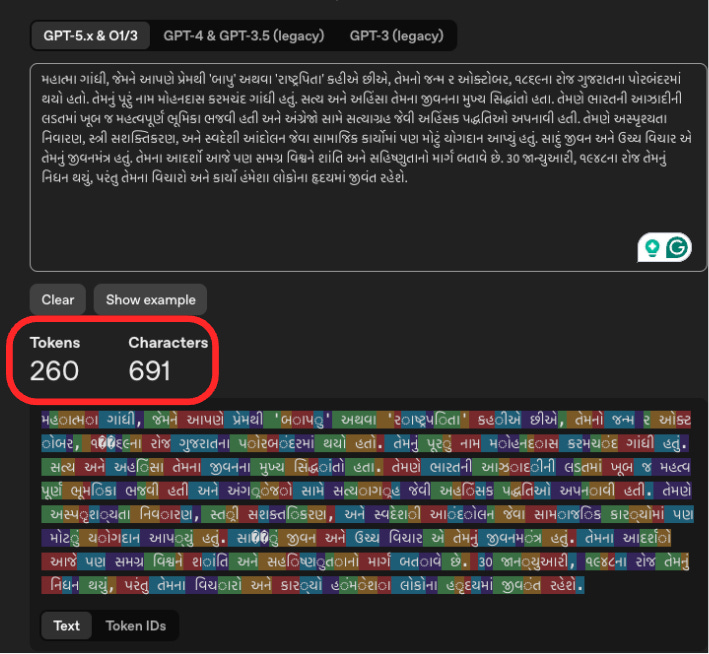
That’s an 86% reduction from GPT-3 to the latest models. And you can see it in the screenshots. GPT-3’s token view is a wall of tiny, fragmented pieces, almost unreadable. GPT-5.x shows clean, recognizable Gujarati words. The tokenizer finally “gets” the script instead of treating it like random bytes.
For a Gujarati-speaking user interacting with an AI product, this isn’t academic. It means their questions cost less to process, the model can hold more of their conversation in memory, and responses come back faster. A language that was effectively a second-class citizen in the tokenizer is now a first-class one.
If you’re building a product that serves multilingual users, this isn’t a minor detail. Fewer tokens means lower API costs, faster response times, and more content fitting into the context window. A comparison on New Relic’s engineering blog noted that GPT-4o’s tokenizer, combined with its lower per-token pricing, could result in roughly a 5x reduction in overall cost for typical RAG requests involving non-English content. That number is scenario-dependent (it’s the combined effect of more efficient tokenization and lower per-token pricing, not tokenization alone), but even half that improvement changes the economics of multilingual products.
And this connects directly back to the context engineering diagram that started this rabbit hole. If your tokens are more efficient, you can fit more meaningful content into each conversation turn. Efficient tokenization effectively “stretches” a fixed context window in terms of semantic content. So a change in the tokenizer can matter as much as a change in the max-token limit itself. The context window isn’t just about the model’s architecture. It’s also about how efficiently you’re packing information into it.
The Tradeoffs Nobody Warns You About
I’d love to say “newer tokenizer = better everything,” but that’s not the full picture.
A research paper published on arXiv found that GPT-4o’s larger vocabulary introduced a new problem. Here’s the mechanism: BPE builds its vocabulary by finding the most frequent byte-pair patterns in training data. But training data includes noisy web content (gaming forums, spam, adult sites). So the algorithm dutifully created long tokens for frequently recurring junk sequences, especially in Chinese. The model then has these tokens in its vocabulary but hasn’t seen them in enough quality contexts to actually use them well.
The result? When GPT-4o encountered these long tokens, it could only produce coherent sentences using them about 45% of the time, compared to 84% accuracy with shorter tokens. GPT-4 (the older model with the smaller vocabulary) actually handled long tokens better.
The researchers found that breaking long tokens into shorter, more common tokens improved both models’ performance. So there’s a real tension: a bigger vocabulary is more efficient for compression, but it can also include tokens the model doesn’t understand well.
This is the kind of nuance that matters for product decisions. “More efficient” and “more accurate” don’t always move in the same direction.
What This Means for Your Product Decisions
So what do you actually do with this information?
Budget differently for multilingual products. If you’re expanding to non-English markets and using current-generation models, your token costs may be dramatically lower than estimates based on older models. Run the numbers with the actual tokenizer, not assumptions.
Test tokenization directly. OpenAI’s Tokenizer tool and the community-built gpt-tokenizer.dev playground let you paste in real user inputs and see exactly how they get tokenized. I’d recommend doing this with actual user queries from your target languages before making architecture decisions.
Watch your context window math. Better tokenization means more content fits in the same context window. If you’ve been chunking documents for RAG based on token counts from an older model, your chunks might be undersized for current models. You could be leaving retrieval quality on the table.
Don’t assume the latest tokenizer is always better for your use case. If your product handles specialized terminology, long compound words, or content in less-represented languages, test specifically for those patterns. The efficiency gains aren’t uniform across all languages and domains.
Quick Cheat Sheet: If You’re Doing RAG with Non-English Corpora
Retest chunk sizes with your target tokenizer. Chunks calibrated for
cl100k_basemay be undersized foro200k_base.Re-estimate cost based on actual tokenization of a sample corpus in your target languages, not English-based assumptions.
Spot-check behavior on domain-specific long tokens. Paste real user queries and domain terminology into the tokenizer tool and look for anything that seems off.
What’s Next
Tokenization is one of those topics that seems boring until you realize it quietly shapes everything: what your AI costs, which languages it handles well, whether it can do basic arithmetic, and how much context it can hold in memory.
I’m still wrapping my head around some of this myself. Early research directions include “learned” or dynamic tokenization, where models could adjust how they segment text based on context rather than relying on a fixed vocabulary. It’s still very much frontier work, but it feels like it could be a genuine unlock for the next generation of models.
For now, go play with the tokenizer tool. Type in some text in different languages. Toggle between models. Watch the token counts change. It’s one of those moments where a technical concept stops being abstract and starts feeling real.
What surprised you most about how tokenization works? Drop a comment below.
[Sources]
Andrej Karpathy’s tokenizer lecture, adapted as a fast.ai book chapter
Microsoft Tech Community: GPT-4o for Indic Languages — multilingual tokenization efficiency analysis
Problematic Tokens: Tokenizer Bias in LLMs — arXiv paper on long token issues in GPT-4o
New Relic: Decoding the Hype on GPT-4o — practitioner cost analysis
Multilingual Token Compression in GPT-o — regex pattern analysis of o200k_base
Toward a Theory of Tokenization in LLMs — Rajaraman et al., 2024
Glossary
Token: A chunk of text (a word, part of a word, or a character) that an LLM processes as a single unit.
Why it matters: You pay per token, and your context window is measured in tokens.
Tokenizer: The algorithm that splits raw text into tokens before it reaches the model.
Why it matters: different tokenizers produce different token counts for the same text, directly affecting cost and context usage.
Vocabulary (vocab size): The total number of unique tokens a tokenizer can recognize. Think of it as the tokenizer’s dictionary of shortcuts.
Why it matters: a larger vocabulary means fewer tokens per input, which means lower costs and more room in the context window.
Byte Pair Encoding (BPE): The algorithm used to build a tokenizer’s vocabulary. It starts with individual bytes and repeatedly merges the most frequent pairs into new tokens until it hits a target vocabulary size.
Why it matters: it’s the core mechanism behind how all current OpenAI tokenizers work.
Parameters: The numerical weights a model has learned during training. They encode everything the model “knows.”
Why it matters: Don’t confuse these with vocabulary. Vocabulary is a lookup table (contacts in your phone). Parameters are the actual knowledge (knowing those people).
Embedding table: The layer where each token in the vocabulary gets a row of numerical weights representing what that token “means” mathematically.
Why it matters: bigger vocabulary = more rows = more parameters in this layer, which is one reason earlier models used smaller vocabularies.
Context window: The maximum number of tokens a model can process in a single request (input + output combined).
Why it matters: More efficient tokenization effectively stretches the context window by fitting more meaning into the same token budget.
r50k_base / cl100k_base / o200k_base: OpenAI’s three main tokenizer generations. The number in each name is the approximate vocabulary size (50K, 100K, 200K).
Why it matters: Knowing which tokenizer your model uses tells you how efficiently your text will be compressed into tokens.
Unicode character categories: Classifications in the Unicode standard that group characters by type (letters, marks, punctuation, etc.). Patterns like \p{Lo} (other letters) and \p{M} (marks/diacritics) Let tokenizers handle non-Latin scripts properly.
Why it matters: This is the technical fix that made tokenization dramatically more efficient for languages like Gujarati, Tamil, and Malayalam.
Diacritics: Marks that attach to base characters to modify pronunciation (like the accent on é, or vowel signs in Tamil and Gujarati).
Why it matters: Older tokenizers split these from their base characters, inflating token counts for languages that rely on them heavily.