
Real Talk AI (Part 1): Real-Time PM Playbook: Trust, Speed & System Design with Madhumita Mantri
From millisecond risk decisions to data contracts and cross-industry lessons, Madhumita shares what it really takes to build real-time AI platforms.

AI in production isn’t just about accuracy; it’s about speed, safety, and trust. Few domains test this harder than online marketplaces, where every millisecond decision impacts fraud losses, GMV, and seller confidence.
For this edition of Real Talk AI, I sat down with Madhumita Mantri, Staff Product Manager at Walmart Marketplace, where she leads real-time AI/ML decision platforms for trust and safety. With prior stints at StarTree, LinkedIn, PayPal, and Yahoo, Madhumita brings a rare cross-industry perspective on how data platforms, AI systems, and product strategy evolve across domains.
TL;DR:
This post focuses on the technical skill set of an AI PM, what it actually takes to build and ship real-time systems that decide in milliseconds and still withstand audits, fairness checks, and rollback pressure.
You’ll learn:
How Madhumita manages tradeoffs behind 200ms decisions
What changes across domains like marketplaces, payments, analytics, and social
How she scopes infrastructure choices like Pinot, Flink, BigQuery, and feature stores and when to say no to all of them
Why this is a two-parter:
This interview went deep, from infra to team structure to GenAI workflows. To keep it digestible, I split it into two:
Part 1 covers system design and technical decision-making
Part 2 shifts into leadership, metrics, scaling, and coaching
Part 1 (this post) focuses on:
Real-time AI decisioning for marketplaces
Cross-industry product differences (Walmart, PayPal, LinkedIn, StarTree)
Platform strategy: Pinot, BigQuery, streaming, feature layers, and when to scale
Part 2 dives into:
Cross-functional leadership as an AI PM
Communicating trade-offs (real-time vs batch)
Defining success with layered metrics and guardrails
Scaling AI from prototype to production
GenAI workflows, mentoring, and cultural practices
Let’s dive in.

Real-Time AI Decision Platforms
At Walmart Marketplace, you build real-time AI/ML decision platforms for trust and safety. What are the unique challenges of building real-time AI systems for marketplace environments?
Most people think real-time AI is just about speed. It’s not. It’s about making fast decisions that won’t blow up in your face an hour, a day, or a quarter later.
Here’s what makes marketplace AI uniquely challenging:
Tight SLAs meet high stakes: You have 50-200ms to decide: approve, deny, route for review, or hold. If you miss that window, the user experience degrades. Make the wrong call and you’re either losing millions to fraud or alienating legitimate sellers who keep the marketplace alive.
Non-stationary data and adversaries: Consumer behavior shifts daily with promotions, weather, and seasonality. Fraudsters adapt even faster. Your model that worked beautifully last Tuesday is leaking money by Friday. Unlike recommendation systems, where drift is gradual, adversaries study your model’s behavior in trust and safety and actively exploit gaps.
Sparse, evolving feature sets: New seller cohorts appear overnight. New devices, payment methods, and geographies create feature combinations you’ve never seen. You need features that can hot-swap, with clear backfill logic and sensible defaults when data is missing, which happens more often than anyone admits.
Streaming joins are brutal: You need to join clickstream data, payment history, device fingerprints, network patterns, and graph features in real time without blowing your latency budget. Pre-aggregation helps, but deciding what to pre-aggregate requires deep knowledge of access patterns and those changes.
Blast-radius control: Even a technically “good” model can still cause disaster if thresholds drift or if you deploy to the wrong segment. You need guardrails, canaries, staged rollouts, and instant kill switches. The system needs to protect you from yourself.
Explainability under pressure: Analysts need to answer “why was this seller blocked?” in seconds, not hours. That means feature attributions, policy traces, and decision history need to be as fast as the decision itself.
Regulatory and fairness constraints: Trust and safety decisions require auditable logic, segment-level fairness monitoring, and clear dispute/appeal paths. You can’t just optimize for accuracy; you must prove your system isn’t systematically biased.
The solution stack:
Apache Pinot for sub-second aggregations and online feature serving
BigQuery for batch + historical joins
Streaming + CDC for freshness
Schema evolution and data contracts
Safe rollout pipeline: offline → shadow → holdout → canary → full
PM Tip: The system is only as good as its guardrails. Real-time AI isn’t just about speed - it’s about making every millisecond decision safe, explainable, and reversible.
Cross-Company AI Evolution
You’ve built AI products across very different contexts. How do AI product requirements differ across these industries?
Summary:
Walmart Marketplace: Priorities are safety, GMV health, and seller fairness. Needs include real-time risk scoring, policy simulation, and appeals. Success is reducing loss, lowering manual review, and improving seller activation.
StarTree: Priorities are anomaly detection and low-latency analytics at scale. Needs include connectors, anomaly templates, and tenant isolation. Success is reducing the mean time to detect and alert fatigue.
LinkedIn: Priorities are network effects, relevance, and abuse mitigation. Needs include graph features, fairness by cohort, and dual-objective ranking. Success is session quality and reduced abuse with minimal friction.
PayPal: Priorities are fraud prevention and compliance. Needs include explainability, adverse action workflows, and regulator-ready governance. Success is loss reduction and audit-proof documentation.
Details:
Walmart Marketplace — Trust & Safety at Speed
The reality: Every risk decision happens in under 200ms and needs to be fair, explainable, and safe. Her team serves multiple stakeholders—risk Ops, Policy, T&S investigators, and Compliance—each with different needs but all demanding speed and auditability.
What matters most:
Real-time risk API that returns both a decision and the reason
Policy simulation so teams can test rule changes without breaking production
Explainability traces that let analysts instantly answer: “Why was this flagged?”
Strict SLOs: p95 latency ≤ 200ms, 99.95% uptime, with continuous fairness and drift monitoring
Success metrics: Lower fraud loss, fewer manual reviews, faster seller activation, fairness gaps held within bounds
What almost broke: Early versions returned decisions fast but couldn’t explain why. When Compliance reviewed the system pre-launch, they nearly blocked it. The team had to rearchitect the feature store to maintain decision provenance at the same speed as the decision itself—adding 40ms to latency but saving the entire project.
PM Tip: Fast decisions are easy. Safe, fair, and explainable ones, in milliseconds, require platform thinking and brutal prioritization. You’re not just building a model; you’re building the entire decision infrastructure around it.
StarTree — Real-Time Anomaly Detection at Scale
The reality: Every customer should have their own anomaly detection system without drowning them in false positives or crushing your infrastructure.
At StarTree, Madhumita led anomaly detection for multi-tenant analytics platforms. Customers monitor different metrics, such as revenue, latency, and inventory, all in real time. The challenge isn’t just detecting anomalies fast; it’s making alerts meaningful enough that customers don’t tune them out.
What matters most:
Out-of-the-box connectors and anomaly templates to reduce setup time from weeks to hours
RCA tools like dimension drilldowns and contribution analysis
Alert quality controls, quotas, merge windows, tuning, to fight alert fatigue
SLOs: Detection ≤ 30s, UI/API p95 ≤ 500ms, 99.9% uptime
Success metrics: Faster time to detect (MTTD), lower alert fatigue scores, faster connector deployment
What almost broke: The initial system was too sensitive. Customers received hundreds of alerts per day and started ignoring them all, including the real ones. The fix required building intelligent alert grouping and user-tunable sensitivity controls.
PM Tip: Real-time detection is only half the battle. The other half is making alerts actionable and trustworthy. An alert system that cries wolf is worse than no system at all.
LinkedIn — Graph-Aware Relevance with Built-In Integrity
The reality: Rank a feed that’s both engaging and safe, at social media speed.
Madhumita worked on systems that optimize graph-based ranking and content integrity. The goal: boost session value without compromising trust. That means real-time personalization powered by graph features, combined with abuse detection, fairness checks, and experimentation guardrails.
What matters most:
Near-real-time graph features (connection strength, engagement history) to drive contextual recommendations
Dual-objective ranking that balances engagement metrics with safety signals
Abuse classifiers with tiered actions (hide, demote, remove) and appeals
Experimentation tooling with automatic guardrails for harm, bias, and fairness
SLOs: Ranker p95 ≤ 150ms, feature freshness ≤ 5 minutes, safety circuit breakers for runaway experiments
Success metrics: Session quality improvements, lower abuse rates, fewer emergency rollbacks, fairness within policy bounds
What almost broke: An experiment boosted engagement by 8% and increased report rates by 40%. The model surfaced borderline content that technically didn’t violate policies but eroded trust. One high-profile user publicly complained about the feed quality, triggering an executive review. The fix required adding “controversial content” as an explicit objective to minimize, not just a post-hoc constraint. It took three weeks to retrain and validate before they could ship.
PM Tip: In social systems, safety isn’t a post-launch filter, it’s part of the ranking logic from day one. Build safety into the experiment design, not just the incident response.
PayPal — Compliance-Grade AI for Risk & Fraud
The reality: Stop fraud and satisfy regulators in real time, with immutable audit trails.
At PayPal, every AI decision had to be accurate, explainable, auditable, and compliant. This meant building risk systems with high precision, stable reason codes, and governance workflows that could withstand legal scrutiny years after the decision was made.
What matters most:
Explainable risk scores with consistent, human-readable reason codes
Adverse action workflows for regulatory notifications (required by law)
Full model governance: model inventory, validation documentation, champion-challenger tracking
Audit-ready case management with immutable lineage—every decision traceable to the exact model version, features, and thresholds used
SLOs: p95 latency ≤ 250ms, 99.99% uptime, audit pack generation ≤ 60s
Success metrics: Lower fraud loss (measured in basis points), zero regulatory findings, fast evidence generation, low overturn rate on disputes
What almost broke: A model update changed risk score distributions, which altered reason code frequencies. Compliance flagged this as a potential fairness issue because certain demographics saw different reason codes than before, even though accuracy improved across all segments. One regulatory audit specifically questioned why “insufficient payment history” became 15% more common for newer customers. The fix required adding “reason code stability” as an explicit constraint during model retraining, which limited how much the team could improve the model in a single release.
PM Tip: When compliance is on the line, velocity means nothing without verifiability. Build AI systems that regulators can trust—not just customers. Document everything, version everything, and make immutability a first-class feature.
What Doesn’t Change — No Matter the Domain
Whether it’s fraud at PayPal, anomalies at StarTree, or feed ranking at LinkedIn, some patterns hold across every AI product Madhumita has shipped:
How you ship:
Rollouts are always staged: shadow → canary → gradual rollout
Auto-rollback triggered by latency spikes, fairness violations, or harm thresholds
Kill switches accessible to on-call engineers without needing deploys
How you align:
Data contracts with versioned schemas and SLOs for freshness and completeness
Clear producer/consumer ownership, no “shared accountability” ambiguity
Weekly syncs between ML, data, and product to catch drift early
How you monitor:
Input drift and output drift are tracked separately
Fairness metrics by segment, not just aggregate
Cost-to-serve per decision (often the first thing to blow up at scale)
On-call playbooks with decision trees and escalation paths
How you measure success:
Scorecard across 4 layers:
Business impact - North Star metrics (GMV, loss, session quality)
Decision quality - Precision, recall, lift, calibration
System health - Latency, uptime, cost
Process maturity - Experiment velocity, rollback frequency, time-to-resolution
PM Tip: The use case changes. The tooling changes. But safe release loops, clear ownership, and layered metrics stay constant. Master these fundamentals, and you can ship AI in any domain.
Data Platform Strategy
You’ve led data search, discovery, and observability platforms. How do you approach building data infrastructure that supports AI product development?
As an AI PM, one of your most important jobs is ensuring that the data platform matches the decision speed your product needs without overbuilding.
Madhumita takes a “lean, real-time stack” approach. That means starting with just enough infrastructure to make reliable, fast, explainable decisions and only scaling up when the use case demands it.
Here’s how she does it:
What’s in the stack (and how a PM is involved):
Kafka + CDC for ingest: The PM ensures the right events are being captured and schema changes don’t break downstream consumers.
BigQuery for batch: PMs define what historical data is needed for model training, audits, and analytics.
Apache Pinot for real-time reads: PMs scope latency SLOs (e.g., “sub-200ms decision time”) that justify using real-time OLAP.
Schema registry + data contracts: PMs drive agreements between data producers (engineering) and consumers (ML, analytics) so features don’t silently break.
Observability tools: PMs define what counts as “data quality”, including freshness, completeness, and drift, and ensure alerts are connected to real product risks.
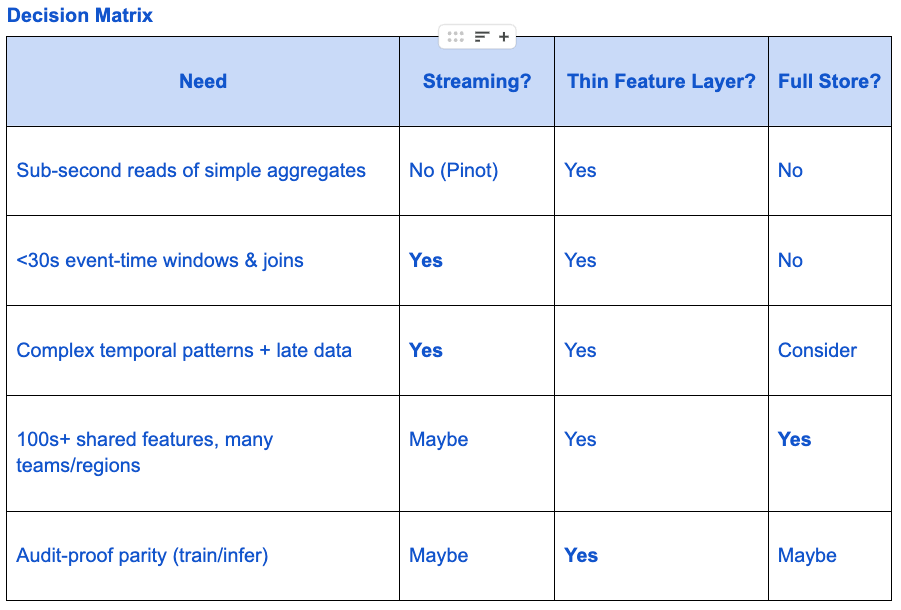
When do you add streaming tools like Flink or Spark?
“Only when the use case truly needs them.”
Madhumita adds streaming pipelines when:
You need event-time joins across sources
The model needs to detect user behavior over time (like bursts or velocity)
You need <30s freshness
Otherwise, she defers using micro-batching or pre-aggregated rollups to keep things simpler and cheaper.
How do you handle the feature layer?
She starts with a thin feature registry, a simple YAML file tracked in Git that defines:
Feature name
Source SQL or stream spec
TTL and freshness SLO
Owner and validations
Features are materialized in BigQuery (for offline use) and Pinot (for online inference).
She only moves to a full-featured store if:
100s of features are being reused
Multiple teams or regions need the same data
Online/offline consistency becomes critical
PM Tip: Don’t aim for the most sophisticated stack; aim for the one that best supports the decision you’re supporting.
Start thin. Add complexity only when the decision, scale, or risk requires it. And stay close to the data quality that keeps your system trustworthy.
Up Next in Part 2:
How Madhumita structures collaboration across DS, MLE, DE, and Ops
Communicating real-time vs batch tradeoffs
Scorecards, guardrails, and North Star metrics
How she scales prototypes into production
Her GenAI workflows, red-teaming strategies, and mentoring advice for AI PMs
About the Contributor
Madhumita Mantri
Staff Product Manager @ Walmart Marketplace
Focused on real-time decisioning, trust & safety, and ML platform strategy.
Previously at LinkedIn, PayPal, Yahoo, and StarTree.
📌 Explore her work and content → linktr.ee/madhumitamantri
Stay in the Loop
If you enjoyed this conversation, you’ll love what’s coming next. Real Talk AI is a no-fluff interview series with AI PMs, DS/ML leaders, and builders sharing how they ship AI products, the decisions, trade-offs, and systems behind the scenes.
Subscribe to aipmguru.substack.com for more interviews, frameworks, and hands-on PM resources.
Share this post with a PM friend who’s GenAI-curious or AI-shipping-stuck.
Have someone in mind for a future edition? Nominate them below with a comment.