
Drift on Foundation Models vs. Your Own Models
Use the AI Drift Map to decide what you can (and can't) control when you build on cloud-hosted foundation models.

Hi, I’m Shaili. I teach AI Builder at UW and shipped AI at Amazon, Disney, Nike, and T-Mobile. AI PM Guru is for PMs who want senior-grade AI interview answers and frameworks that stand the test of launch. Practitioner-real, no hype.
This is Post 2 of 2 in the Drift Series. The playbook. Post 1 was the map. If you haven’t read it, start there — this post assumes the vocabulary from post 1.
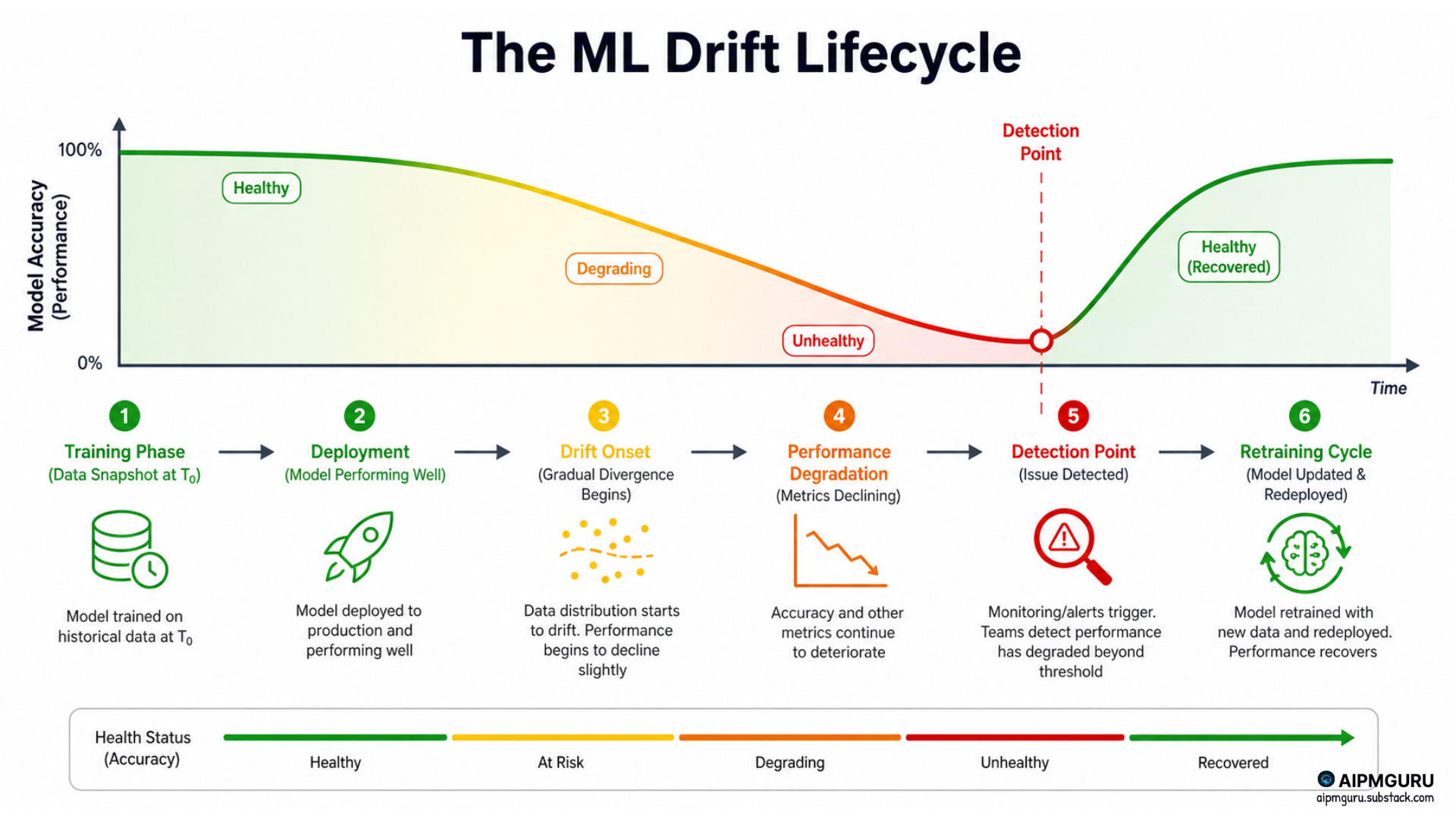
In the first post of this series, we built the AI Drift Map. A one-page legend for how AI systems quietly go stale.

The point was simple. When a model “drifts”, something has changed:
Inputs changed (data/feature drift),
Rules changed (concept drift),
Outcomes changed (label drift),
Plumbing changed (domain / upstream drift), or
Decisions changed (prediction drift).
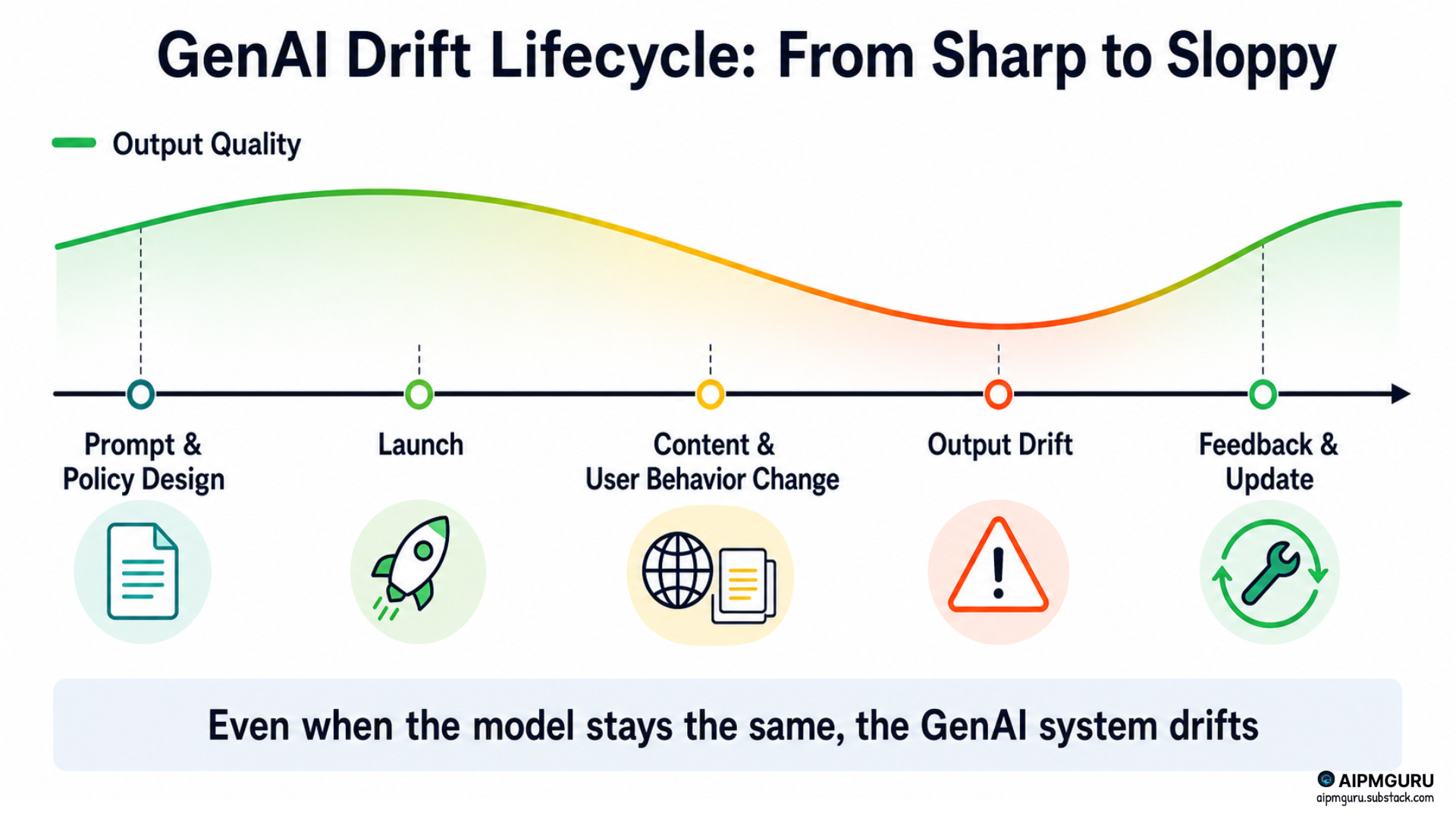
That taxonomy doesn’t change when you move from classic ML to cloud-hosted foundation models like GPT, Gemini, or Claude. What changes is who controls what, and which levers you can pull when drift shows up.
This post is about that control plane.
Foundation models vs your own models, in drift terms
When I say “building on foundation models,” I mean three common patterns:
Calling a cloud-hosted foundation model API directly (OpenAI, Anthropic, Google).
Using a managed foundation model on a cloud platform (Bedrock, Vertex, Azure OpenAI, watsonx).
Fine-tuning a foundation model, but still running it on the provider’s infrastructure.
When I say “your own models,” I mean:
Classic ML models, you train and deploy.
LLMs or foundation models you self-host and fully control (weights and infrastructure both).
Same physics. Two different architectures. And the architecture decides which knobs you can turn.
Same drifts, different ownership
The high-level view.
Here’s the table I’d hand a PM walking into their first AI architecture review.
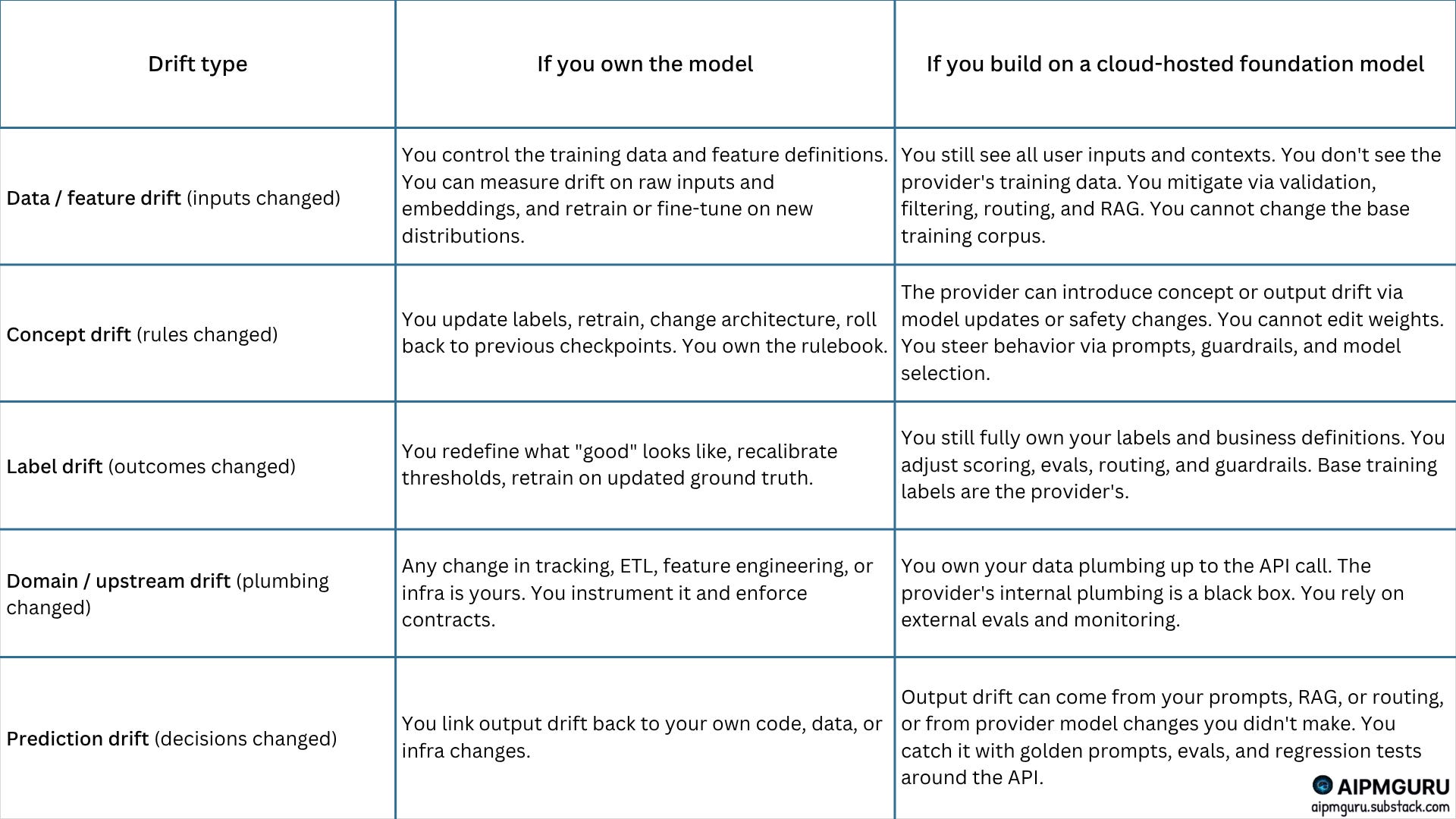
The takeaway, in one line:
Owning the model gives you more levers at the model level. Weights, data, architecture.
Building on cloud-hosted foundation models shifts your power to system-level levers. Prompts, routing, RAG, UX, evals.
The drift map stays the same. The knobs you can actually turn are very different.
Two drift stories
Let’s make this concrete.
Story 1: Drift on your own model (a churn model)
You ship a churn model for a B2B SaaS product.
Inputs changed: you expanded from U.S. enterprise customers to SMBs in new regions.
Outcomes changed: churn rate jumps from 4% to 10% after pricing changes.
Decisions changed: the model still labels accounts as “low risk” that are now clearly at risk.
Your runbook:
Update labels and calibration targets.
Retrain on newer data with the new mix.
Add features that capture the new dimensions (region, segment).
Update thresholds and monitoring.
Everything lives inside your stack. You can change data, model, or both.
Story 2: Drift on a foundation model (a support copilot)
You ship a support copilot built on a cloud-hosted foundation model with RAG.
Inputs changed: support tickets shift from “how-to” questions to “complex billing” and “policy edge cases”.
Plumbing changed: your RAG index hasn’t been refreshed in months. New policy changes are missing.
Rules changed: the provider updates the hosted model sometimes without a version bump on your end, and behavior shifts, becoming more cautious or simply different in the cases you care about.
Decisions changed: the copilot becomes more evasive and less helpful on exactly the hard cases you care about.
Your runbook is different:
Prompt drift: tighten system prompts and policies.
RAG drift: refresh indexes, update retrieval filters, seed your evals with new documents.
Provider drift: run golden prompts and evals on a schedule, catch behavior changes early, switch model versions or vendors if needed.
You never touch the weights. You have plenty of room to steer behavior.
The Drift Readiness Checklist
Five steps. Doable on a normal sprint.
Step 1: Inventory your AI surfaces. List 2-3 critical AI use cases (fraud, churn, recommendations, copilots). Label each as “own model,” “foundation model,” or “hybrid.” If you can’t get to three, one is fine. Start with the highest-stakes one.
Step 2: Minimal monitoring. Log inputs, outputs, and at least one business KPI. Add one simple drift signal for inputs, outputs, and outcomes. None of this needs to be elaborate. A nightly job and a Slack alert are enough.
Step 3: Golden tests. For foundation models, create 10-50 golden prompts with expected behavior. Run them on every change, plus weekly. For your own models, maintain a basic eval set with labels. (I wrote a walkthrough on building your first eval that lays this out step by step.)
Step 4: One-page runbook. For each drift box (inputs, rules, outcomes, plumbing, decisions), define two things: who investigates first, and what the first lever is. Prompts/RAG vs data/model/pipeline.
Step 5: Governance. Make the AI Drift Map and the Drift Readiness Checklist part of your design reviews and postmortems. The map is only useful if your team actually uses it.
I turned this into a one-page Drift Readiness Checklist you can paste into your workspace and use in design reviews. Grab it here.
What you’ve got after two posts
You now have:
A map (Post 1): the vocabulary and visuals for all the ways AI systems drift.
A guide (Post 2): how drift behaves on your own models vs cloud-hosted foundation models, and what to do about each.
Use the map when you’re explaining drift to stakeholders, students, or new teammates. Use the runbook when you’re planning your AI architecture or reviewing a production incident. Use the checklist when you’re not sure where to start.
I wrote about evals and synthetic data earlier this year, and both of those land harder once you have the drift map in your head. If you haven’t read them, they’re the next stops in this same conversation.
Related posts
If this was useful, forward it to one person on your team who needs it. And if there’s something here you’d push back on, or an AI PM question you wish I’d answered, hit reply. I read every reply. The forwards and DMs are the signal that doesn’t show up on any dashboard.
What’s the one AI PM resource you’d hand to a non-engineer PM trying to skill up? Drop it below, I’ll compile.